
Every person in business knows that the most valuable asset you can have in the decision-making process is data. The more data we have, the better the decision we can make. But this data is not good on its own – without an accurate analysis, it is just data.
So, the real challenge isn’t how to collect data, but how to process and analyze it in a way that allows us to improve our business. This is what we do. We extract value from massive volumes of data that can lead to game-changing insights.
The benefits of data science
Before we talk about the how, let’s talk about the why. Data Science and business value are not only about “making more sales”. There are lots of ways in which this value can be used for our benefit.
From a business standpoint, it can be used to seize new opportunities, identify unforeseen needs, detect new business models, and even predict how likely it is that they are successful.
From a value perspective, it can make a huge difference to users or customers with a better product or service. Better predictive models in healthcare mean more healthy people. Improved accuracy in image recognition means better maps and directions.
Better trained voice recognition models means data can be ported to more devices, allowing almost everyone (with or without a heavy accent!) to have a virtual assistant.
The benefits of data science are as diverse and wide-ranging as the organizations themselves.
Phase 1: Situation analysis
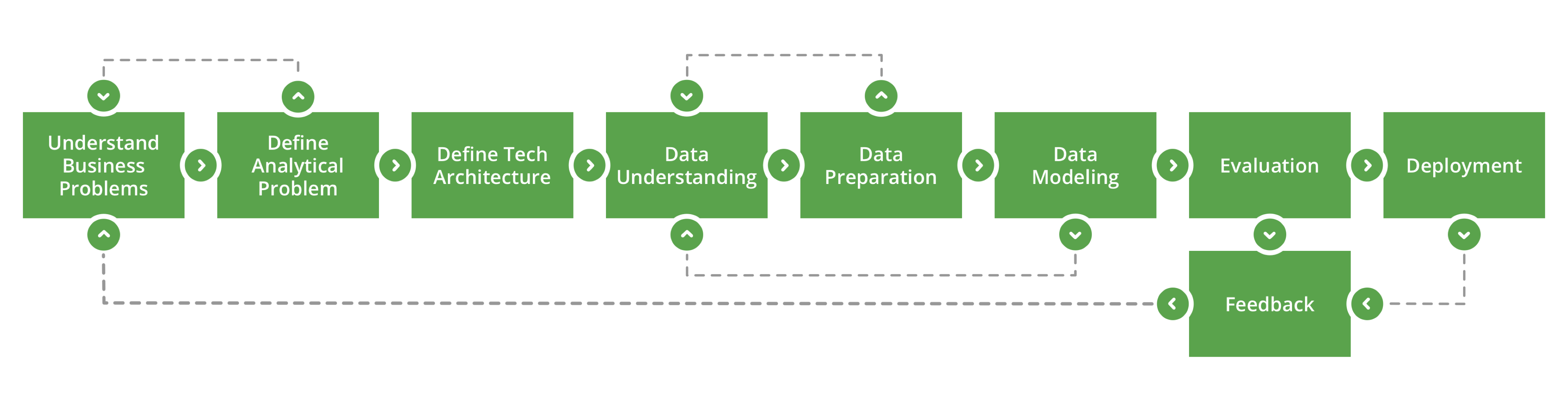
First, since context is everything when it comes to properly interpret data, we work closely with our users to understand the business and the business problem. It is crucial to understand the nuances of the business domain – this is why we look at data science to understand a particular aspect of a company – often it’s something essential to turning out a great product.
In this early stage, we are able to formulate and define an analytical problem. It begins by translating the problem that we want to solve into a hypothesis that we will prove or disprove. We choose this hypothesis with care so that either result will provide a better understanding of the problem itself.
For instance, “making the presentation blue will drive better sales” is only a useful hypothesis if it holds true, but instead “the presentation color is correlated with sales” is a useful hypothesis even if proven false, because it allows us to dig deeper.
At the end of this phase, having gained knowledge about the business, having identified the problems that we want to solve, and having created a good set of hypotheses to work with, we can define the technical architecture. This will be comprised of the systems that support our analysis and data ingestion, which in turn will be used to for our analysis.
We find that it is usually better defined once the problems themselves are identified because we can scale the systems to the specific needs of the customer. Otherwise, companies might spend a lot of time trying to integrate all of their data into a single data lake, where only just part of that data was relevant to the actual problem.
Phase 2: All about data
Having set the stage and prepared the team, we can now focus on the data itself. Collecting the data is only the first step. We then proceed to analyze the data from a perspective of quality. Is it consistent? Is it complete? Does it contain outliers, and if so, what do they mean? Can we trust the results we get from using this data, and what is the significance of each data point?
We also analyze the data as a set: what are the relationships between the data sets that we collect? Do they complement or do they contradict each other? What story does each data set tell about a particular scenario?
This leads us to a process of data understanding and data cleaning. This is a process that requires cross-functional knowledge: business intelligence and data science knowledge. We need to be able to “speak data” to our data scientists and “speak business” to our stakeholders, to ensure that everyone is on the same page.
Phase 3: Methods and Hypotheses
Here’s where the action begins, so, of course, it’s the part we love the most. This phase is where we begin data modeling: looking at statistical methods and seeking to extract meaning from the results. Note that this is also an iterative phase, with informed feedback. As we reach immediate conclusions, we validate if they are meaningful to the business. In the best case, we have some quick wins on our hands, and in the worst case, we are just in time to make adjustments to our understanding of the data.
At this point, we’re able to confirm or reject our hypotheses from Phase 1. This is some of the value that we provide, but the journey does not end here.
Data Science is a tricky business because there are no absolute certainties. This means that every conclusion is tied to a certain level of probability – we make sure to communicate that in a very simple way so that business can decide to use this information with full knowledge of the risks involved.
On one hand, we need to perform a technical evaluation of our models to get these probabilities, but on the other hand, the business stakeholders need to perform an evaluation of what they want to do with the newly acquired knowledge. As we said before, knowledge is power, and power is not to be wielded blindly. We need to evaluate and assess what we have learned.
Phase 4: Final Results
In some cases, the cycle ends here, where the new information already powers us to explore further into new directions and strategies. If so, we document the results and we present it to the business team.
In some other cases, this work can be “productionalized” – that is: made into a system that can make the same predictions with the information that we gained. This is usually called deployment.
In any of these cases, after having won this round, we assess our standing and we decide what the next best use of our time is, to improve the business value better yet, and moving back to Phase 1 for a new round of data discovery.
Data expertise brings it all together
It takes a team of data experts to move a project from Phase 1 to Phase 4. We employ four different types of experts to make everything come together:
- Data Analysts: help with the understanding of the data and the initial clean up and recovery from multiple data sources.
- Data Engineers: help with automating the process of recovery and integration with multiple systems to leave the data in an easy-to-consume format for modeling.
- Data Scientists: run statistical inference tests and create models that work with the outcomes of the data.
- DevOps: help ensure the setup and correct functioning of the infrastructure behind these efforts.
Together, these experts work to help our customers achieve business impact through the use of data.